
I. INTRODUCTION
In recent years, facial expression recognition techniques have been being more accurate due to advances of various deep learning approaches. Facial expression recognition techniques can be widely applicated in variety of fields such as medical, health care, robotics and self-driving vehicles. There are several challenges in this technique. The first is that it is highly dependent on datasets and the second is about applying its dynamic features. Most of application fields of facial expression recognition require real time responses of facial expression. Thus, there are a lot of attempts to improve facial expression recognition accuracy by extracting temporal features. In this paper, we discuss many researches for more accurate facial expression recognition and propose a new 3DAGN (3D appearance and geometric network) pipeline for detecting well both appearance and temporal features. At last, we mention about our simple experiment.
This paper is organized as follows. In section 2, related works are introduce with four detailed categorizations. Section 3 includes our proposed method. Section 4 will mention experiment results and section 5 concludes this paper.
II. RELATED WORKS
Datasets taken in the controlled environment of the laboratory for facial expression recognition like CK+ (extended Cohn-Kanade) [1] and JAFFE(Japanese female facial expression) [2] are used for many researches. On the other hand, SFEW (static facial expression in wild) [3] dataset which contains dynamic facial images that are close to the real world is one of the challenging dataset of this task. There are also researches for analzing facial expression from unaffected datasets such as CASME (the Chinese academy of sciences micro-expression) [4] and DISFA (denver intensity of spontaneous facial action) [5] dataset. For recognizing the facial expression along time axis, the dataset should have sequences to detect temporal information. Thus, nonsequential datasets like JAFFE, SFEW are not suitable for real time facial expression recognition task. Datasets available in this type of study are typically CK+, MMI [6], Oulu-CASIA [7] and AFEW (acted facial expression in the wild) [8]. In this paper, we use CK+ dataset for our experiment.
Temporal appearance network means the network which extract temporal features from facial input images. It can be divided into two groups depending on how it input images into the network. The first network uses a few images as input while the second uses some features extracted through series of pre-processing processes as input. [9] introduces the 3D Inception-ResNet model which uses 10 frames of sequence as input. Fan et al. [10] use 3 frames as input of CNN-RNN model and Convolution 3D model and achieved an accuracy of winner of EmotiWi 2016. Liu et al. [11], on the other hand, uses an expression video clip as a spatio-temporal manifold formed by dense low-level features. Many types of features are used as much research about this field as. Sun et al. [12] reveal the comparison of accuracy by features. According to their study, there are 8.8% accuracy improvement when recognizing facial expression with LBP (local binary pattern) [13] features compared with grayscale images.
These networks extract temporal features using geometric information of input face images. There are several geometric based approaches like Canny edge detection and AAM (active appearance model) [14], MRASM (multi-resolution active shape model) and LK-flow [15] method. Facial landmark point is also one of the typical geometric feature. [16], [17] and [18] use facial landmarks as geometric feature of their networks. Hasani et al. [9] additionally utilize landmarks to emphasis the difference between the importance of main facial components and other parts of the face which are less expressive of facial expressions. Kim et al.[19] use not whole landmark points but landmark difference in the face area of major AU’s which have the most active information for geometric network.
The method combined section 2.2 with section 2.3 is the temporal hybrid network. [19] is a kind of static hybrid network and [20], [21] are temporal hybrid networks. Jung et al.[20] use two architectures of the deep networks. Their two networks receive an image sequence and facial landmark points as input respectively. They propose a new method for integrating two separate networks. Since temporal hybrid networks deal with temporal features from two perspective, they generally perform better than networks that use only one feature.
III. PROPOSED METHOD
Our proposed method is similar to hybrid method among many approaches mentioned in section 2. Fig. 1 shows the pipeline of proposed 3DAGN.
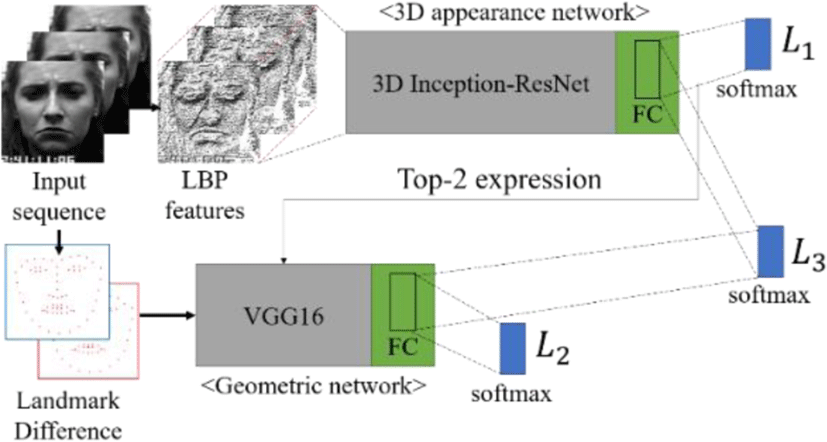
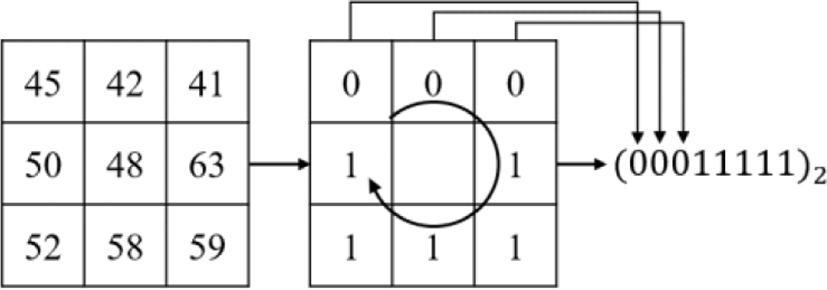
As we mentioned in section 2.1, the accuracies are usually higher when inputs are given as features. Thus, our proposed method also takes an LBP feature as input for getting better performance. Figure n shows that how to make LBP features. After making an LBP feature for each image, input features are stored in an array in the form of values. To encode LBP feature is shown in Fig. 2.
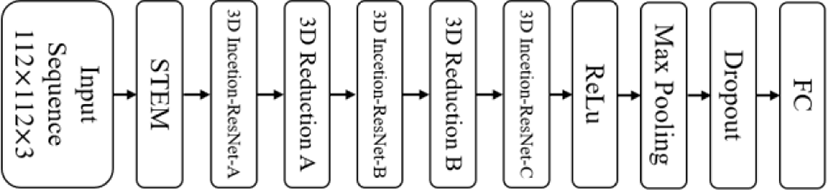
Our proposed method uses 3D Inception-ResNet model [9] to extract appearance features from network. 3D Inception-ResNet model is modified version of original 2D Inception-ResNet model [22]. We take shallower network than original network. Fig. 3 is the proposed 3D appearance network structure. Due to paper limits, layers are showed in block form and detailed layer configurations follow [9]. According to [19], the error is biased in the second highest expression label. Thus, we pass the labels that have best and second prediction probability of appearance network to the geometric network to overcome the error occurred at the second most likely.
Geometric Network uses a landmark image pair of peak expression and non-peak expression as input. Firstly, we have to make expression set which consists of peak and nonpeak. Fig. 4 shows an example of expression set.

Then we can extract 68 landmark points from each of them. But not all points are used as they are. When a person makes facial expression, facial areas such as brow, eyes, nose and lips change more than other else. These parts contain a lot of information about facial expression, so we assign weights on these landmark points. After this process, landmark differences according to changes in facial expression are obtained. Then we can emphasize the change of the most expressive area. These difference images will be taken as input to the geometric network.
Geometric network is a role to find the correct expression which passed from the Top-2 expression of appearance network. This network takes VGG16 network [23] structure.
The model for each expression set is trained and stored and the model corresponding to the Top-2 from appearance network will be selected to train geometric network.
The loss function used to learn 3DAGN is defined as follows:
where L1, L2 and L3 are the loss function of 3D appearance, geometric networks and both respectively. For convenience, we call 3D appearance network, geometric network, and the integrated network by network 1, 2, and 3, respectively. Each loss function is a cross entropy loss function, which is defined as follows:
where i is network number, and are the j-th value and j-th output value of softmax of the network 1 and 2 ground truth label respectively. Finally, c is the number of classes, L2 has 2 classes. From last linear fully connected layer of each networks, we can get logit values. The loss function for network 3 is defined as follows:
where l1,j and l2,j are j-th logit values of network 1 and 2. As a result, we use three loss functions in the training step and utilize only result of network 3 for test. We apply dropout method to reduce overfitting problem.
IV. EXPERIMENTS
In this paper, we introduce the experiment result of the initial structure of the network corresponding to the 3D appearance network what we propose. The dataset used in this experiment is formed in the shape of 112×112×3 by cropping only face area, resizing and combining three consecutive frames from CK+ dataset. This network consists of four 3D convolution layers, three 3D max-pooling layers, one batch normalization layer and two fully connected layers with dropout. The structure of the network used in the experiment is shown in Fig. 5.

Every convolution layer has 3×3×3 size of kernel and every max pooling layer has 2×2×2 size of kernel. The active function is ReLu. At the end of the network, seven emotions are extracted by softmax function. This network is trained for about 100 epochs with Adam optimizer.
Table 1 shows the experiment results on CK+ dataset of researches that performed about facial expression recognition for a sequence of several input frames including our proposed method. Comparing to other state-of-the-art works, our method achieves comparable result. Result of [20] is a combination of appearance and geometric networks, so our network will also be able to achieve outperformed results using geometric feature additionally.
| Methods | Accuracy(%) |
|---|---|
| 2DIR with CRF [24] | 93.04 |
| 3DIR [9] | 93.21 |
| STM-ExpLet [11] | 94.19 |
| DTAGN [20] | 97.25 |
| Ours 3DAGN | 97.22 |
V. CONCLUSION
In this paper, we discuss some novel facial expression recognition approaches. Although facial expression recognition task still has difficulty that is dependent on dataset, we have confirmed that using features as input in appearance network and the hybrid method of combining appearance and geometric network are more effective for facial expression recognition. We achieve an accuracy of 97.22%, a comparable result of the state-of-the-art results by using the initial network structure which is applicable to the proposed 3D appearance network. In the future, we will organize a new network according to our proposed structure with detailed parameter tuning to get reasonable results in cross-database. Eventually, we will experiment on AFEW dataset to get outperformed result.
