





I. INTRODUCTION
Nowadays, the flight simulation plays an increasingly important role in aerospace science and industry because the technology can reduce significantly the cost and time than implementing the actual flight test to achieve the same accuracy. Especially in preliminary design and pilot training, the accuracy of flight simulator is important to secure that the simulator is possible to reproduce the real flight behavior. That requires a highly precise and large aerodynamic database (AeroDB), which provides the aerodynamic coefficients of vehicle for various flight conditions and vehicle configurations encountering over the whole mission. In real engineering work, AeroDB is constructed by running various kinds of analysis tools with different levels of fidelity to ensure that the database is as accurate as possible. That is because each method has its own limits of accuracy and cost, indeed, a single method may not be able to perform at all flight conditions on the whole flight mission envelope. Generation of AeroDB in traditional methods is expensive and long-time work. Collecting data from flight tests is sometimes highly expensive, even with support from powerful computational methods, it still may require years and high-performance computer systems to compute all required computational cases for a targeting AeroDB. That may make construction of AeroDB in a direct way impossible due to limits of budget and time. However, using simplified model of real system may reduce computational cost but reduce the accuracy of resulted data as well. Therefore, metamodels are widely used to replace the original systems with a considerably reduced computational cost [3]. There are many popular metamodels, such as kriging, polynomial response surface and radial basis function. These methods allow to construct an approximation model of original system from given sample data. However, the quality of metamodels is considerably influenced by the amount of sample points. For example, the more sample points usually the more information on the given original system, but it also means a higher cost, while fewer sample points may reduce the computational cost but lead to inaccurate metamodels which reflect fewer properties of the original system as well.
To solve this problem, variable-fidelity metamodeling (VFM) methods based on multiple fidelity models have been increasingly popular. In VFM methods, a high-fidelity (HF) model is one that reflects all physical characteristics of the system with expensive computational cost, e.g. computational fluid dynamics (CFD) and physical experiments, while a low-fidelity (LF) model is one that describes the main properties of the system with lower computational demand, e.g. numerical empirical formulate. Some existing popular VFM methods to be discussed in this paper are: co-kriging introduced by Kennedy and O’Hagan (2000) [2], hierarchical kriging (HK) introduced by Han and Gortz (2012) [4] and improved hierarchical kriging (IHK) introduced by Hu (2016) [3]. These VFM methods generally allow constructing an approximation model of system and generating multi-dimensional database by using samples of data in two levels of fidelity. However, if the LF model is not good enough to describe the main properties of the HF model, in other word, the difference between LF model and HF model is considerably different, VFM models should need more HF sample point to correct the accuracy of the model. That raises a problem that how to improve the VFM model without paying additional cost for more HF sample data. It is possible that improvement of LF model can be implemented by using an additional data set, called middle-fidelity (MF) data, which is cheaper than HF data but can be better in describing properties of HF model than the current LF model in the same work. This direction is an economical way to improve the VFM model but also requires an alternative VFM methods, which is able to analyze different data sets with three levels of fidelity. The goal of this research is to develop an alternative VFM algorithm, called three-level kriging (3LK), which is based on HK method that can combine 3 sets of data into a single set and maximize the accuracy.
This article is organized as follows. Details of the proposed method are discussed in Section II, including the deviation of 3LK and strategy for turning model. In the same section, a numerical example and an engineering case are provided to validate the proposed method, followed by a conclusion in Section III.
II. METHODOLOGY
In this paper, a three-level kriging (3LK) model is constructed by a combination of two HK models. The proposed method is an evolution of HK method to solve a data fusion problem with input of three data sets.
HK is a VFM method suggested by Han and Gortz (2012). This method assumes that sets of sample points have two levels: the HF sample points, high accurate and extracted from expensive methods, and the LF sample points extracted form methods that are significantly less computationally demanding. Compared to HF sample points, LF points are less accurate but easier to obtain; therefore, the LF model is used to capture the global properties of the HF model, and HF samples are used to correct error of model. Hence, the HK method is an effort to approximate the HF function in a form written as:
where ŷlf(x)is the LF model which can be directly built by a kriging model [1] with LF sample points. ρ is a scaling factor indicating the influence of the LF model on the prediction of the HF model, Z(x) is a stationary random process having zero mean and a covariance, written in form as:
where, σ2 is the process variance of Z(.) and R(x,x′) is the spatial correlation function, which only depends on the Euclidean distance between two points, x and x’. The HK predictor can be written in form as:
where ρ = (FTR−1F)−1FTR−1ys is scaling factor, indicating how much the LF and HF functions are correlated to each other, and is calculated by the initial HF sample points yhf = [Ŷhf (x1), Ŷhf(x2), …, Ŷhf (xnhf)] and estimated responses of LF model at locations of HF sample points F =[flf(x1), flf(x2), …, flf (xnlf)]. And r(x) is a vector presenting the correlation between unknown point and HF sample points.
In the study, the method assumes that the given data sets have three levels of fidelity, which are low-fidelity (LF), middle-fidelity (MF) and high-fidelity (HF) sampling data as:
Using 3 data sets of Slf,Smf and Shf, approximation models are modelled as:
Here, y1(x) is a LF model, and it can be directly built by kriging model with LF sample points. Z1 (x) and Z2(x) are stationary random processes having zero mean and covariances:
Hence, the three-level kriging predictor can be written in form as:
where
Correlation function is required to be calculated at the early stage of constructing the model, and it is written in form as:
where Θ = (θ1, …, θm) ∈ Rm are the hyper-parameters to be turned and m denotes the dimension of design space. The most popular form of this correlation function is Gaussian exponential function. It can be calculated by:
Θ = (θ1, …, θm) is a width parameter that affects how far a sample point’s effect extends. A low θj means that all points will have a high correlation, with Y(xj) being similar across our sample, while a high θj means that there is a significant difference between the Y(xj)′sθj[1]. The unknown parameters Θ are founded using maximum likelihood estimation and the likelihood functions can be formulated as:
where
where Θ1, Θ2 denote vectors of θ and both σ and R are the functions of Θ. The numbers of sample points in MF and HF sets are denoted by nmf and nhf, respectively. Optimal solutions of hyper-parameter can be solved by using a genetic algorithm.
To verify the proposed metamodeling method, a one-dimensional numerical example is used to test the approximation capability of 3LK model. In this case, the HF function is taken from Forrester, Sóbester and Kean (2008) [1]. The expression of HF function is:
The MF function is:
The LF function is:
The x locations of sampled data of LF model, MF model and HF model are:
Two points are placed at the boundary of the design space to avoid extrapolation, while others are placed within it; in addition, no point is located close to the global minimum or maximum of the function.
Here, three different accuracy metrics are adopted to verify the accuracy of each method: (1) Mean Absolute Error (MAE) (2) Maximum Absolute Error (MaxAE) (3) Coefficient of multiple determination (R2). MAE and R2 represent the global accuracy of the function, while MaxAE reflects the local accuracy of the function. The expressions of three metrics are:
where nt represents the total number of test points, ŷi is the predict value at test points, yi denotes the true value at test points.
As well as the proposed 3LK is used here to make the comparison among different VFM methods. Fig. 1 shows the results of four different methods for the test case. The solid line represents behavior of the actual model, and the filled diamonds, stars and circles represent given HF, MF and LF sample points, respectively. The dash line represents the result using 3LK model to fit the HF function. It is noted that only 3LK model is built by using sample points of all LF, MF and HF data sets, in contrast, kriging model is built by using 2 HF sample points alone and other models are built by using 11 LF sample points and 2 HF sample points.
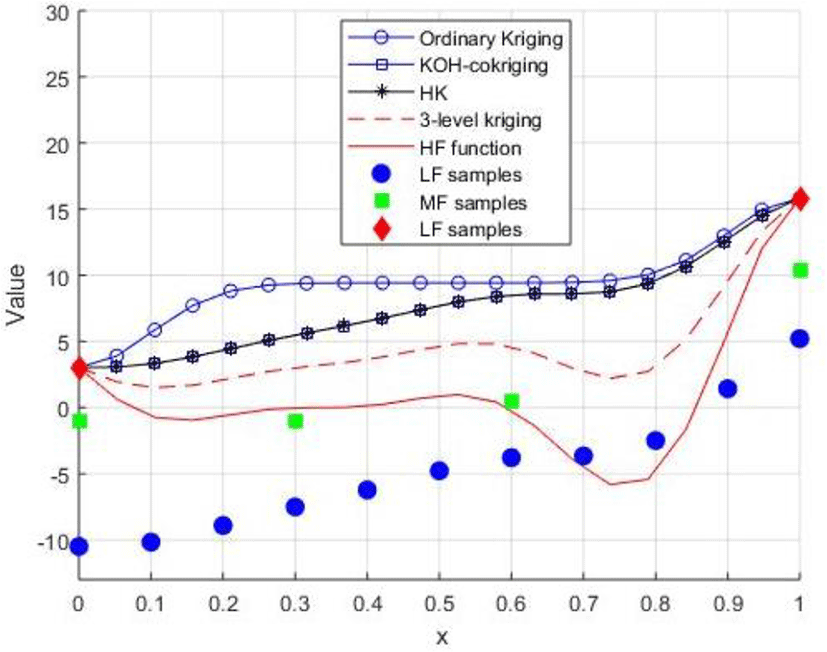
It can be concluded that the proposed 3LK outperforms other methods, since in most locations, it is the closest to the HF function. That is because the MF sample points provide 3LK model more information about HF function to correct the prediction, noting that the number of MF sample points is smaller than LF sample point as well as MF data is cheaper than HF data. The ‘HF data’ is sometimes very expensive or difficult to be extracted in actual engineering data fusion problems. In order to enhance the prediction of HF data when adding more LF sample points does not make more improvement, an additional set of MF data is used to enhance the model. The MAE and MaxAE of different methods are listed in Table 1.
| Method | MAE | MaxAE | R 2 |
|---|---|---|---|
| Kriging | 8.5111 | 15.2408 | 0.3076 |
| Co-kriging | 6.7748 | 14.7731 | 0.3236 |
| HK | 6.7842 | 14.7854 | 0.3226 |
| 3LK | 3.7310 | 8.1480 | 0.8116 |
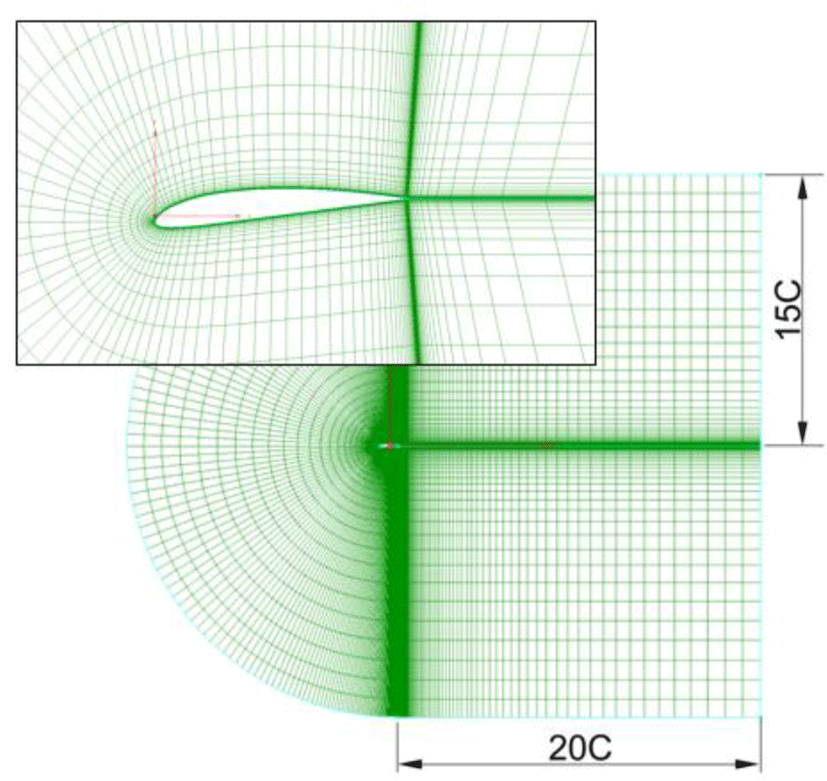
In this section, the validation of proposed method is illustrated through constructing database of the aerodynamic coefficient of an existing airfoil Clark Y. There are two independent variables are considered, such as Mach number,M, and angle of attack, α. The ranges for variables are 0.1 ≤ M ≤ 0.8 and −20° ≤ α ≤ 20°. The database is generated by running independently three different methods, such as Ansys Fluent (16 points), Boundary Layer Method called “BLM” (44 points) and Potential Flow Method called “PFM” (328 points). The data given from Fluent, BLM and PFM are used as the HF, MF and LF sample points, respectively. In this case, the LF and MF sample data are gained by running fast computational algorithms in Javafoil tool, the HF sample data is computed by using Fluent 15.0 simulation tool and Sparlart-Allmaras one-equation turbulent model. The grid consists of about 350,000 elements is used as seen in Fig. 2. It took only minutes for Javafoil runs but approximately 23 h for CFD runs on a 3.0 GHz CPU computer.
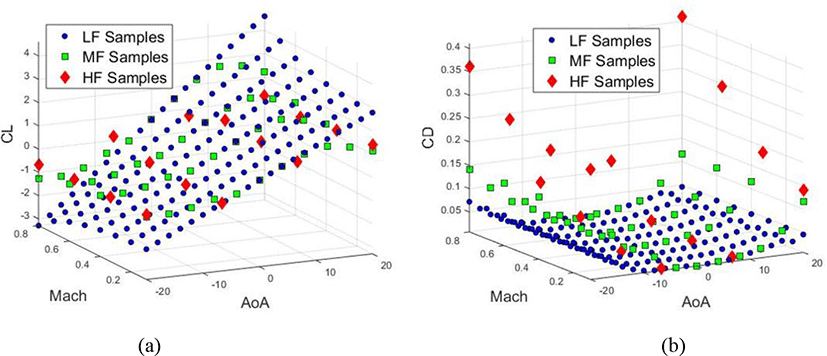
For training metamodels, the conventional kriging model is constructed by using 16 HF sample points alone. Cokriging, HK, IHK are constructed by using 328 LF sample points and 44 MF sample points. Finally, a 3LK model is constructed by using all mentioned data set. The distributions of various sets of sample data in the design space are shown in Fig. 3 and prediction surfaces of CL and CD resulted from various methods are illustrated in Fig. 4. An additional 70 points are randomly selected to verify the accuracy of the built approximate models and results of global and local errors are listed in Table 2.
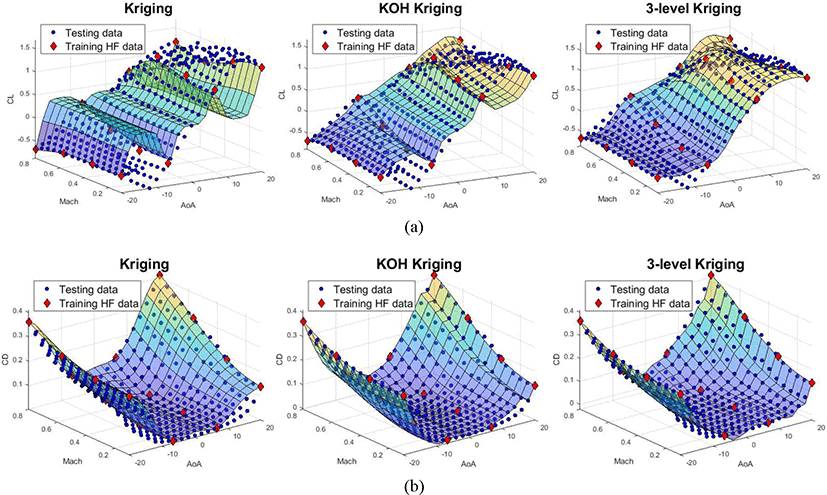
The 3LK model certainly impoves on both the global and local performances compared to ones of other methods. It can also be concluded from Table 2 that the proposed method can provide more accurate metamodel since it has the smallest MAE and Maximum and the largest R2 values. It is also proved that developing HK model into 3LK is appropriate choice because HK shows better improvement on both glocal and local performances than ones of other existing methods , though HK is slightly worse than IHK in prediciton of CD and local performaces in prediciton of CL. However, global error of HK is much smaller than that of IHK in CL. It can be undoubted that the key factor making outperformance of 3LK is the additional set of MF sample points, noting that MF sample points are just in a small amount and much cheaper than HF sample points. Indeed, adding only small number of MF sample points, which can more accuratly capture the global trend of HF data, may help significantly improve the performance of metamodel, especially when the number of HF sample points is critically small - a situation in which many of conventional VFM methods may have poor performance. However, this kind of situation is very common in practical problems such as construction of AeroDB in flight simulation application. Another advantage of the proposed method is that it has a more stable performace than other methods when the numer of HF sample points is small. This statement is proved in the next investigation. The Fig. 5 shows the global and local performace of different models in prediciton of CL with various numbers of HF sample points. In this investigation, an additional number of Fluent sample points are added to train metamodels while reamaining the number of LF and MF sample points.
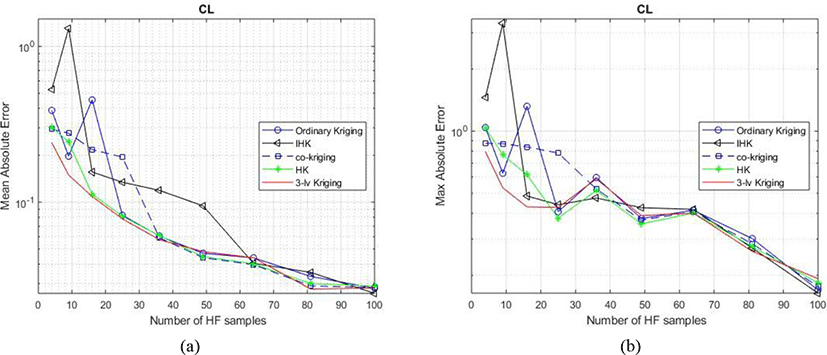
Once again, it can be concluded from figures that the proposed method provides a more accurate and stable metamodel in global and local performances compared to other algorithms, with nearly the smallest MAE, MaxAE and the largest R2 with various numbers of HF sample points. The 3LK outperforms from other algorithms in poor condition of small number of HF sample points. In the same condition, ordinary kriging, IHK and co-kriging face poor convergences in both global and local errors. Indeed, only when the number of HF points is more than 36, kriging and co-kriging methods begin to converge into the same fashion as 3LK model does. Although the proposed method may require more computational cost to obtain the MF sample points, this additional computational cost is likely to be offset by the saving in calls required for HF model.
III. CONCLUSION
In this paper, a method for building variable-fidelity metamodel from a hierarchy of data sets with different levels of accuracy is introduced, which is developed from an existing method. This method has more advantages than the origin and allows to improve a surrogate model built on expensive HF data using information from a cheaper one. It is particularly useful when the HF data is very expensive. That is a popular issue in engineering data fusion problems, which mostly require a large amount of data. An example of constructing an aerodynamic database for airfoil Clark Y has been introduced to prove the performance of the proposed method. This work can be extended further to be applied for construction of multidimensional aerodynamic database for actual aircraft in flight simulation applications.



